Leo Lightburn

I am a PhD student at Imperial College London. My research focuses on algorithms for enhancing very noisy speech signals.
Why not listen to some audio samples, produced using a neural network based algorithm developed during my PhD.
View my publications.
Contact me.
PhD supervised by Mike Brookes.
Latest projects
My current work focuses on improving the intelligibility of noisy speech signals using enhancement algorithms based on feed-forward and recurrent neural networks. This research has several possible applications including hearing aids, forensics, and voice communications in adverse environments.
In a recent project, working with colleagues in the Speech and Audio Processing Laboratory, I helped to integrate a neural network based speech enhancement algorithm that was developed during my PhD into a proposed multiple-microphone hearing aid system, leading to substantial improvements in predicted intelligibility in very noisy conditions.
My research is primarily focused on situations where speech has been contaminated by very high levels of interfering noise, resulting in a reduction in the intelligibility of the speech (the percentage of words understood). Examples of noises include other speakers, vehicles, aircraft and machinery. In these situations, the goal of the enhancement algorithm is to improve the intelligibility of the noisy speech.
In very high levels of noise, conventional speech enhancement algorithms are typically unable to improve intelligibility. In recent years, however, several studies have reported promising results using algorithms based on machine learning. These algorithms typically have a structure similar to the one shown below.
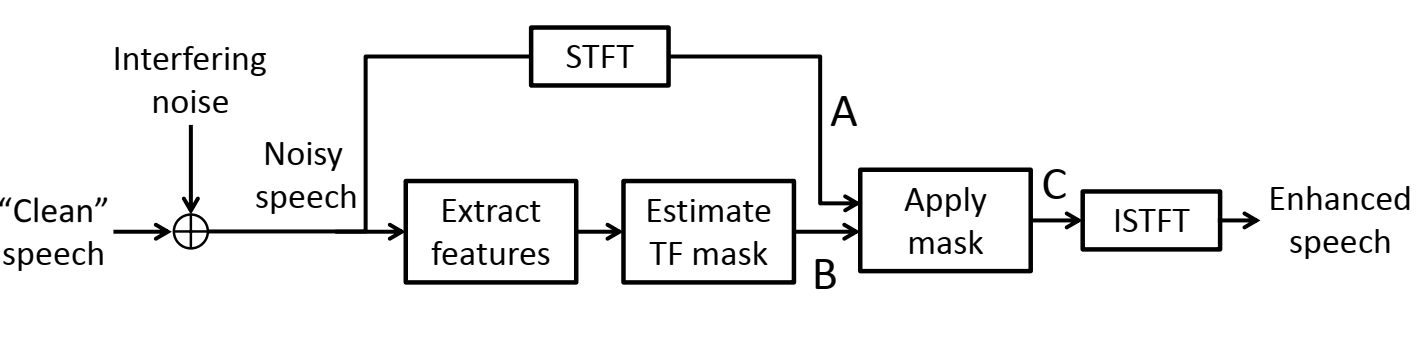
In the first two (lower) blocks in the diagram, features are extracted from the noisy speech and fed, as inputs, into a machine learning algorithm which estimates a bounded two-dimensional quantity known as a “Time-Frequency mask”. The noisy speech is then converted into the time-frequency domain using the Short-Time Fourier Transform (STFT), and the estimated mask is applied to the signal. Finally, the enhanced speech is converted back into the time-domain.
The spectrograms below show examples of a clean speech signal (top), the speech after being contaminated by noise from multiple interfering speakers (A), the mask produced by the “Estimate TF mask” block (B), and the enhanced speech (C). The labels A, B and C correspond to the labels on the diagram above.
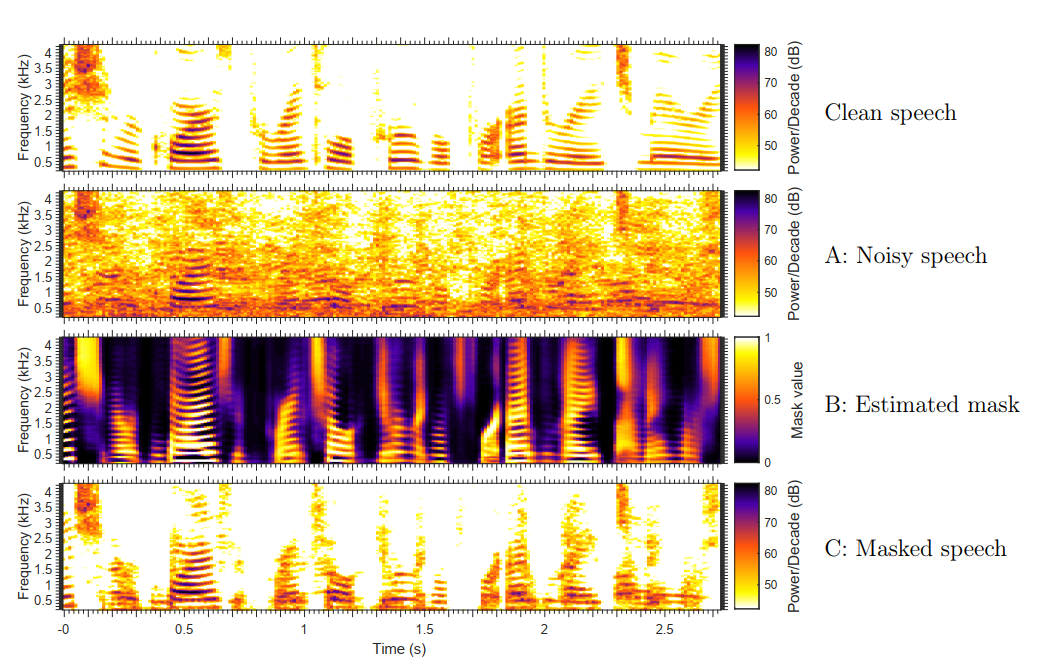
From the spectrograms, it is clear that the estimated mask (B) mirrors the time-frequency pattern of energy in the original clean speech. Equivalently, the mask captures the pattern of spectro-temporal amplitude modulation in the clean speech. These modulations, which are known to be important for speech intelligibility, are then reintroduced into the noisy speech by the “Apply mask” module, resulting in an increase in predicted intelligibility. After applying the mask, the modulation pattern in the speech (C) is now much closer to the pattern in the clean speech (top).
The approach I am currently exploring in my research involves training a neural network to estimate a modified version of a target mask developed earlier in my PhD. This target mask optimises the predicted intelligibility of the binary masked speech, where the predicted intelligibility is obtained using another algorithm developed during my PhD. Our proposed approach to applying the mask involves using the mask to obtain a probability distribution on the clean speech and incorporating this as prior information into a modified speech enhancer.
Audio examples
The enhanced speech in these samples was produced using the neural network based approach developed during my PhD (described above).
Example 1 - machinery noise
Noisy speechEnhanced speech
Clean speech
Example 2 - babble (interfering speakers)
Noisy speechEnhanced speech
Clean speech
Example 3 - helicopter cockpit
Noisy speechEnhanced speech
Clean speech
Example 4 - jet aircraft
Noisy speechEnhanced speech
Clean speech
Neural network architectures
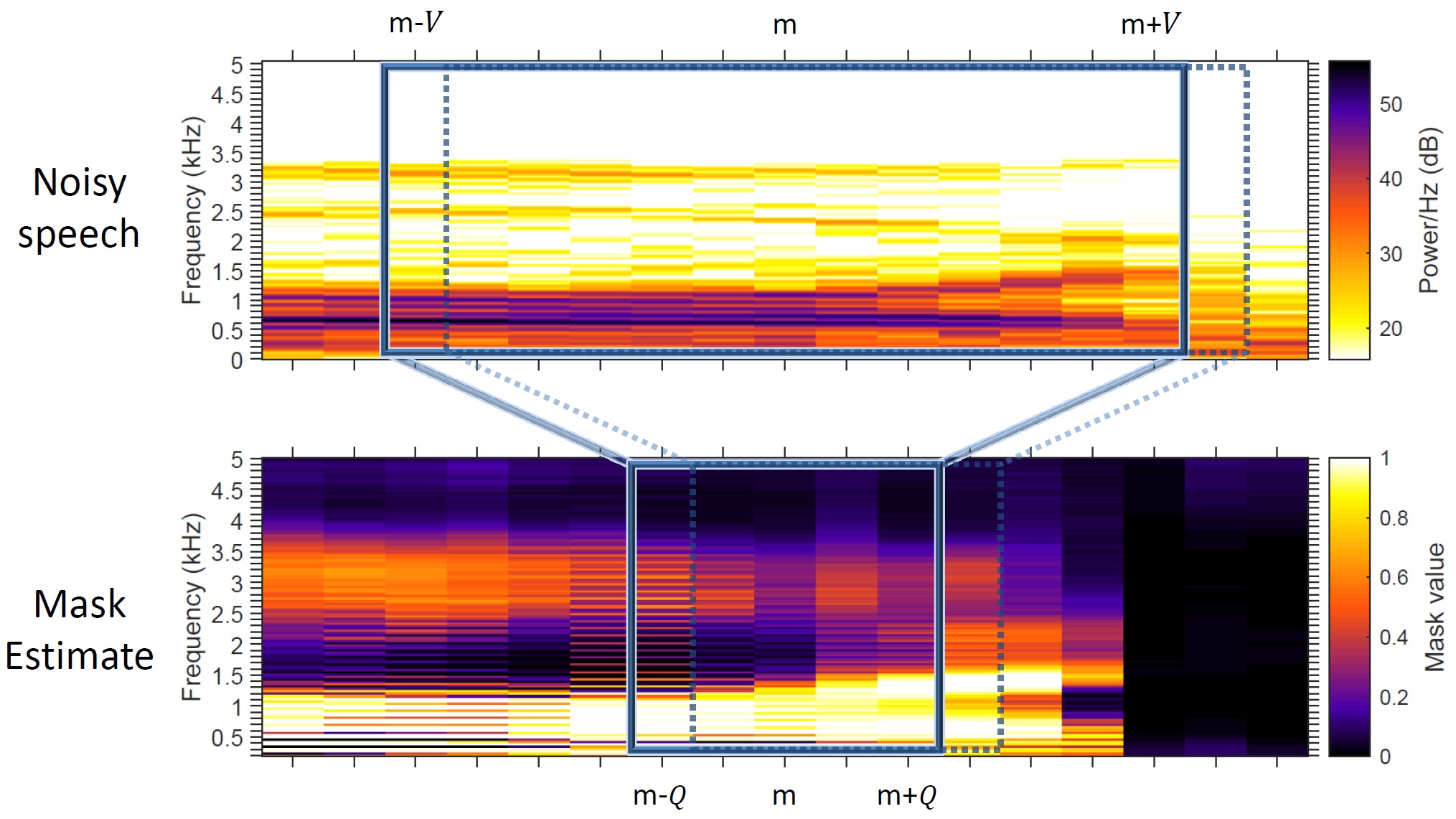
From the spectrograms of speech, it is clear that the speech in neighbouring frames (discrete points in time) is highly correlated. This correlation can be exploited to estimate the mask more accurately. One approach is to use a “feature window” covering several frames. This is illustrated below. Features within a sliding window (upper plot) are concatenated and used as inputs to a feed-forward neural network, which simultaneously estimates all of the mask values within another sliding window, the “estimation window” (lower plot). The windows then shift forward by one frame to the position shown by the dotted line, and the procedure is repeated. Using an estimation window results in several mask estimates for each mask bin, which are averaged to produced the final mask estimate. The purpose of averaging several mask estimates is to lessen the effect of individual mask estimation errors.
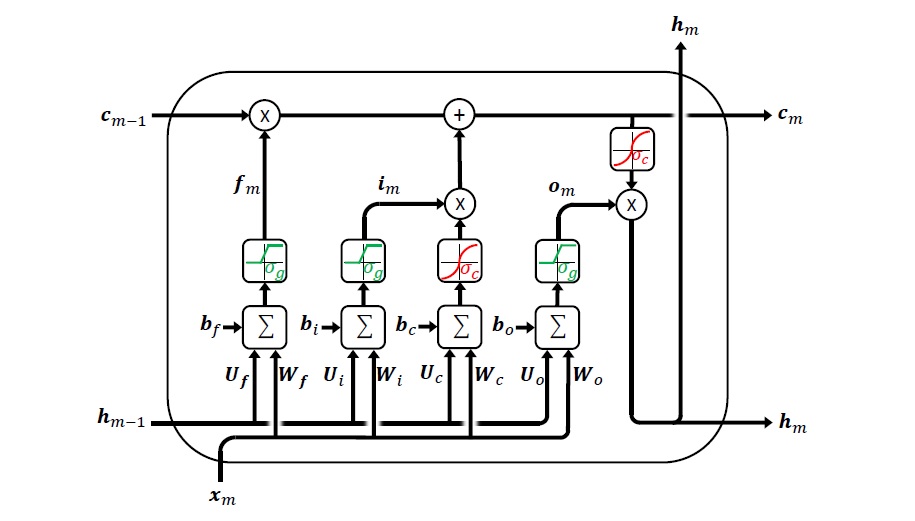
An alternative way of exploiting the correlation in the signal is to use a recurrent neural network with Long Short-Term Memory (LSTM). A single LSTM layer or “cell” is shown below. The LSTM cell contains internal memory in the form of a cell state whose value is controlled by two gates—a forget gate and an input gate. The forget gate controls the amount of information to discard from the cell state, and the input gate controls the degree to which the cell state is updated with new values. When the forget gate is “on” and the input gate is “off”, the cell state remains unchanged over successive frames. This enables LSTMs to retain information in their memory for long periods, which in turn enables them to model long dependencies between inputs and outputs.
In two upcoming journal papers, and my thesis, I will investigate different choices of feature sets, target masks, estimation algorithms, and methods for applying the estimated masks.
Publications
- A. Moore, L. Lightburn, W. Xue, P. Naylor, and M. Brookes, Binaural mask informed speech enhancement for hearing aids with head tracking, in Proc. Intl Wkshp Acoustic Signal Enhancement, Tokyo, 2018
- L. Lightburn, E. D. Sena, A. Moore, P. A. Naylor, and M. Brookes, Improving the perceptual quality of ideal binary masked speech, in Proc. IEEE Intl. Conf. on Acoustics, Speech and Signal Processing, 2017.
- L. Lightburn and M. Brookes, A weighted STOI intelligibility metric based on mutual information, in Proc. IEEE Intl. Conf. on Acoustics, Speech and Signal Processing, 2016.
- L. Lightburn and M. Brookes, SOBM – a binary mask for noisy speech that optimises an objective intelligibility metric, in Proc. IEEE Intl. Conf. on Acoustics, Speech and Signal Processing, 2015.